使用AI解决Doris性能不足问题
Apache Doris 是一个基于 MPP 架构的高性能、实时的分析型数据库,以极速易用的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。
但是,对于Power BI而言,它只是一个数据源,而且是IO性能很差的一个数据源,差到想一次性导入千万行级别的数据都各种报错。要么是查询超时,要么是内存达到了上限。又不可能因为Power BI需要一次导入这么多数据而提高Doris服务器的配置,这里感叹下微软的弹性配置是真好用。那么,问题要怎么解决呢?先问下gpt4

追加查询
首先想到的是分成多个条件查询,然后在pq里使用追加查询合并为一张新表。很遗憾,这个方法并不可行。这个其实和另一个问题很像,在pq里合并两张表,其中一张表A设置为不刷新不加载,但是前台刷新时,合并后的表中是有刷新表A的内容的,因为有查询依赖。
分页查询
pq里无法实现,只能优化查询语句了,比如每次只查询100万行。嗯,问题又来了,一直在用aure sql,对mysql的语法并不熟悉,没关系,继续问gpt4。gpt4给出的相对来说已经是一个可用的代码版本了,只需要修改其中的参数,然后就正常加载了几千万行数据

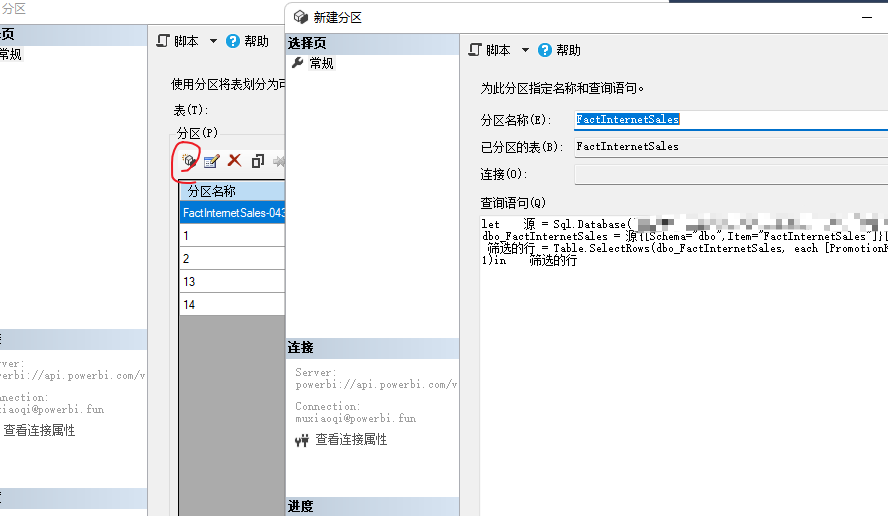
这里又会有一个问题,数据每年的增量也是千万级,而且历史数据会经常被修正,所以,又进一步对数据集进行了分区 修改,之后按年来刷新数据,这里要注意,分区功能需要高级容量工作区才可以,并且通过XMLA方式修改过的语义模型是不支持下载了(使用git恢复通过XMLA修改过的数据)。分区可以使用SSMS,也可以使用Tabular Editor3
思考
这只是一个很小的问题,更多的只是提供一个解决问题的思路,漫漫打工路上,我们一定会遇到各种各样的凭既往的经验或者能力无法解决的问题,那么怎么快速地用已有地知识或者工具解决未知的问题,这是很多人不具备的,也是我一直在学习的。目前我的方法是把一个大问题拆分成很多小的问题,然后依次解决这些小问题,解决小问题的过程中随时呼叫给我的打工的各种AI。
2023年一直在部门中推广AI,chatgpt4,copilot,bard,claude,gemini pro api,总之能用来通过提出一个高质量问题,就能得到一个高质量答案的AI都会去使用。2024年,也会继续在工作中通过使用AI来提高效率,不再限于知识库,而是更多应用到workflows中去,反正就是抱着玩的心态,可能更容易坚持?毕竟玩的时候一定是开心快乐的。